matplotlib#
# For interactive plots
from bokeh.plotting import figure, show, output_notebook
from bokeh.models import TeX
output_notebook()
A snapshot of the development on the matplotlib project.
Issues#
query_date = np.datetime64("2020-01-01 00:00:00")
# Load data
with open("devstats-data/matplotlib_issues.json", "r") as fh:
issues = [item["node"] for item in json.loads(fh.read())]
glue("devstats-data/matplotlib_query_date", str(query_date.astype("M8[D]")))
New issues#
Show code cell source
newly_created = [
iss for iss in issues if np.datetime64(iss["createdAt"].rstrip("Z")) > query_date
]
new_issues_closed = [iss for iss in newly_created if iss["state"] == "CLOSED"]
new_issue_lifetime = np.array(
[
(np.datetime64(iss["closedAt"].rstrip("Z"))
- np.datetime64(iss["createdAt"].rstrip("Z")))
for iss in new_issues_closed
],
).astype("m8[h]") # in hours
glue("matplotlib_num_new_issues", len(newly_created))
glue("matplotlib_num_new_issues_closed", percent_val(len(new_issues_closed), len(newly_created)))
glue("matplotlib_new_issue_median_lifetime", f"{np.median(new_issue_lifetime)}")
4713 new issues have been opened since 2020-01-01, of which 3705 (79%) have been closed.
The median lifetime of new issues that were created and closed in this period is 76 hours.
query_date = np.datetime64("2020-01-01 00:00:00")
# Load data
with open("devstats-data/matplotlib_issues.json", "r") as fh:
issues = [item["node"] for item in json.loads(fh.read())]
glue("matplotlib_query_date", str(query_date.astype("M8[D]")))
Show code cell source
title = (
f"Lifetime of issues created and closed in the last "
f"{(np.datetime64(datetime.datetime.now()) - query_date).astype('m8[D]')}"
)
h, bedges = np.histogram(
new_issue_lifetime.astype("m8[D]").astype(int), bins=np.arange(30)
)
p = figure(
width=670,
height=400,
title=title,
tooltips=[("lifetime", "@right days"), (r"# issues", "@top")],
)
p.quad(top=h, bottom=0, left=bedges[:-1], right=bedges[1:])
p.xaxis.axis_label = "Issue lifetime (days)"
p.yaxis.axis_label = "# Issues"
show(p)
Time to response#
Show code cell source
# Remove issues that are less than a day old for the following analysis
newly_created_day_old = [
iss for iss in newly_created
if (np.datetime64(datetime.datetime.now())
- np.datetime64(iss["createdAt"].rstrip("Z"))) > np.timedelta64(1, "D")
]
# TODO: really need pandas here
commented_issues = [
iss for iss in newly_created_day_old
if any(
e["node"]["__typename"] == "IssueComment" for e in iss["timelineItems"]["edges"]
)
]
first_commenters, time_to_first_comment = [], []
for iss in commented_issues:
for e in iss["timelineItems"]["edges"]:
if e["node"]["__typename"] == "IssueComment":
try:
user = e["node"]["author"]["login"]
except TypeError as err:
# This can happen e.g. when a user deletes their GH acct
user = "UNKNOWN"
first_commenters.append(user)
dt = (np.datetime64(e["node"]["createdAt"].rstrip("Z"))
- np.datetime64(iss["createdAt"].rstrip("Z")))
time_to_first_comment.append(dt.astype("m8[m]"))
break # Only want the first commenter
time_to_first_comment = np.array(time_to_first_comment) # in minutes
median_time_til_first_response = np.median(time_to_first_comment.astype(int) / 60)
cutoffs = [
np.timedelta64(1, "h"),
np.timedelta64(12, "h"),
np.timedelta64(24, "h"),
np.timedelta64(3, "D"),
np.timedelta64(7, "D"),
np.timedelta64(14, "D"),
]
num_issues_commented_by_cutoff = np.array(
[
np.sum(time_to_first_comment < cutoff) for cutoff in cutoffs
]
)
# TODO: Update IssueComment query to include:
# - whether the commenter is a maintainer
# - datetime of comment
# This will allow analysis of what fraction of issues are addressed by
# maintainers vs. non-maintainer, and the distribution of how long an issue
# usually sits before it's at least commented on
glue(
"matplotlib_num_new_issues_responded",
percent_val(len(commented_issues), len(newly_created_day_old))
)
glue("matplotlib_new_issues_at_least_1_day_old", len(newly_created_day_old))
glue("matplotlib_median_response_time", f"{median_time_til_first_response:1.0f}")
Of the 4712 issues that are at least 24 hours old, 4384 (93%) of them have been commented on. The median time until an issue is first responded to is 2 hours.
Show code cell source
from bokeh.transform import dodge
title = f"Percentage of issues opened since {query_date} that are commented on within..."
x = [str(c) for c in cutoffs]
y = 100 * num_issues_commented_by_cutoff / len(newly_created_day_old)
p = figure(
x_range=x,
y_range=(0, 100),
width=670,
height=400,
title=title,
tooltips=[(r"%", "@top")],
)
p.vbar(x=x, top=y, width=0.8)
p.xaxis.axis_label = "Time interval"
p.yaxis.axis_label = "Percentage of issues commented on within interval"
show(p)
First responders#
Show code cell source
first_commenter_tab = pd.DataFrame(
{
k: v
for k, v in zip(
("Contributor", "# of times commented first"),
np.unique(first_commenters, return_counts=True),
)
}
)
first_commenter_tab.sort_values(
"# of times commented first", ascending=False
).head(10)
| Contributor | # of times commented first | |
|---|---|---|
| 287 | jklymak | 981 |
| 465 | tacaswell | 537 |
| 472 | timhoffm | 450 |
| 95 | QuLogic | 435 |
| 155 | anntzer | 293 |
| 390 | oscargus | 194 |
| 312 | ksunden | 164 |
| 422 | rcomer | 160 |
| 463 | story645 | 152 |
| 247 | github-actions | 76 |
Pull Requests#
Show code cell source
with open("devstats-data/matplotlib_PRs.json", "r") as fh:
prs = [item["node"] for item in json.loads(fh.read())]
# Filters
# The following filters are applied to the PRs for the following analysis:
#
# - Only PRs to the default development branch (e.g `main`)[^master_to_main]
# are considered.
# - Only PRs from users with _active_ GitHub accounts are considered. For example,
# if a user opened a Pull Request in 2016, but then deleted their GitHub account
# in 2017, then this PR is excluded from the analysis.
# - PRs opened by dependabot are excluded.
# Only look at PRs to the main development branch - ignore backports,
# gh-pages, etc.
default_branches = {"main", "master"} # Account for default branch update
prs = [pr for pr in prs if pr["baseRefName"] in default_branches]
# Drop data where PR author is unknown (e.g. github account no longer exists)
prs = [pr for pr in prs if pr["author"]] # Failed author query results in None
# Filter out PRs by bots
bot_filter = {
"dependabot-preview",
"github-actions",
"meeseeksmachine",
"pre-commit-ci[bot]"
}
prs = [pr for pr in prs if pr["author"]["login"] not in bot_filter]
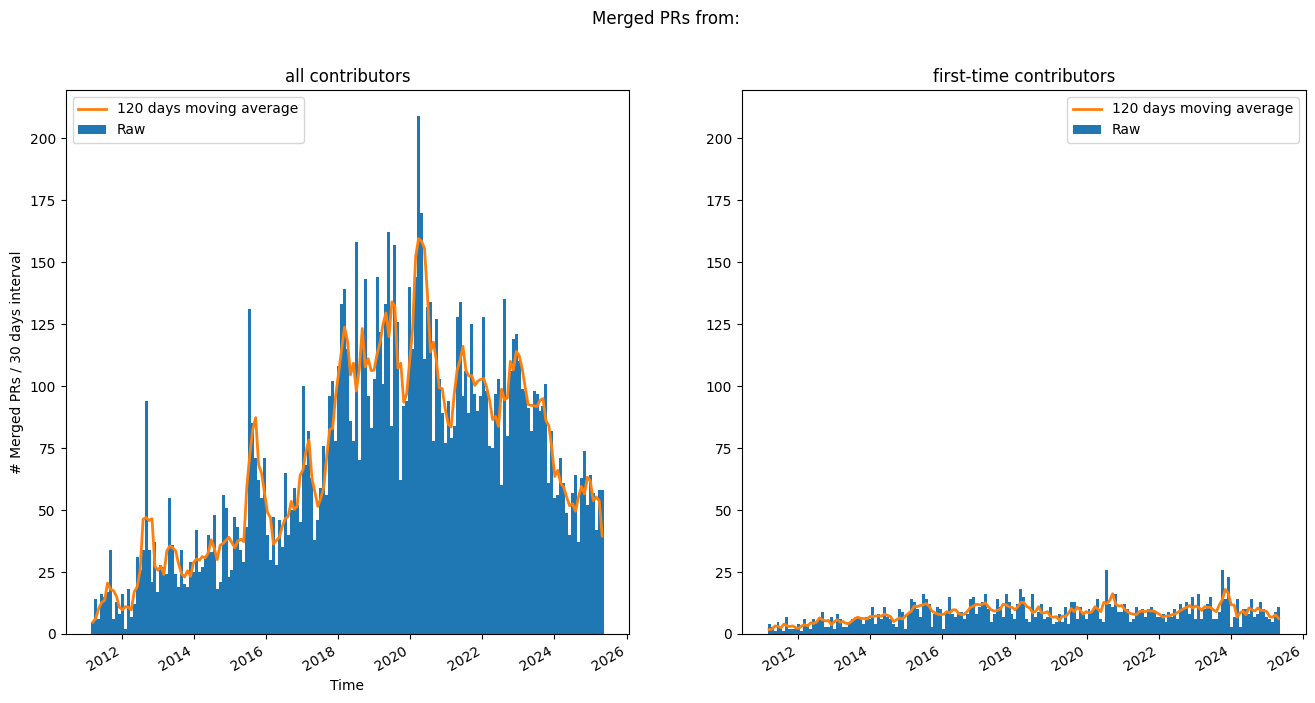
Merged PRs over time#
A look at merged PRs over time.
Show code cell source
# All contributors
merged_prs = [pr for pr in prs if pr['state'] == 'MERGED']
merge_dates = np.array([pr['mergedAt'] for pr in merged_prs], dtype=np.datetime64)
binsize = np.timedelta64(30, "D")
date_bins = np.arange(merge_dates[0], merge_dates[-1], binsize)
h_all, bedges = np.histogram(merge_dates, date_bins)
bcenters = bedges[:-1] + binsize / 2
smoothing_interval = 4 # in units of bin-width
# First-time contributors
first_time_contributor = []
prev_contrib = set()
for record in merged_prs:
try:
author = record['author']['login']
except TypeError: # Author no longer has GitHub account
first_time_contributor.append(None)
continue
if author not in prev_contrib:
first_time_contributor.append(True)
prev_contrib.add(author)
else:
first_time_contributor.append(False)
# Object dtype for handling None
first_time_contributor = np.array(first_time_contributor, dtype=object)
# Focus on first time contributors
ftc_mask = first_time_contributor == True
ftc_dates = merge_dates[ftc_mask]
h_ftc, bedges = np.histogram(ftc_dates, date_bins)
fig, axes = plt.subplots(1, 2, figsize=(16, 8))
for ax, h, whom in zip(
axes.ravel(), (h_all, h_ftc), ("all contributors", "first-time contributors")
):
ax.bar(bcenters, h, width=binsize, label="Raw")
ax.plot(
bcenters,
np.convolve(h, np.ones(smoothing_interval), 'same') / smoothing_interval,
label=f"{binsize * smoothing_interval} moving average",
color='tab:orange',
linewidth=2.0,
)
ax.set_title(f'{whom}')
ax.legend()
fig.suptitle("Merged PRs from:")
axes[0].set_xlabel('Time')
axes[0].set_ylabel(f'# Merged PRs / {binsize} interval')
axes[1].set_ylim(axes[0].get_ylim())
fig.autofmt_xdate()
# TODO: Replace this with `glue` once the glue:figure directive supports
# alt-text
import os
os.makedirs("thumbs", exist_ok=True)
plt.savefig("thumbs/matplotlib.png", bbox_inches="tight")
/tmp/ipykernel_4630/3088127314.py:3: UserWarning: no explicit representation of timezones available for np.datetime64
merge_dates = np.array([pr['mergedAt'] for pr in merged_prs], dtype=np.datetime64)
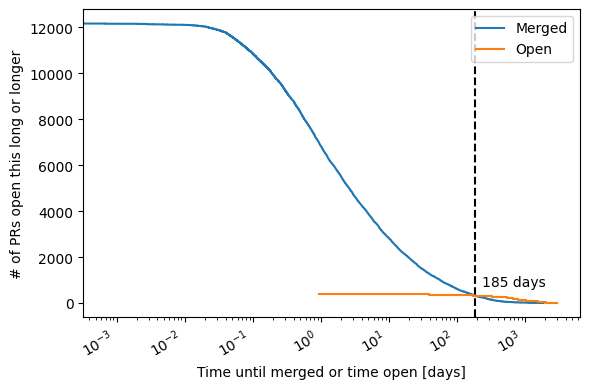
PR lifetime#
The following plot shows the “survival” of PRs over time. That means, the plot shows how many PRs are open for at least these many days. This is separated into PRs that are merged and those that are still open (closed but unmerged PRs are not included currently).
Show code cell source
merged_prs = [pr for pr in prs if pr['state'] == 'MERGED']
lifetimes_merged = np.array(
[isoparse(pr["mergedAt"]) - isoparse(pr["createdAt"]) for pr in merged_prs],
dtype="m8[m]").view("int64") / (60 * 24) # days
lifetimes_merged.sort()
#closed_prs = [pr for pr in prs if pr['state'] == 'CLOSED']
#lifetimes_closed = np.array(
# [isoparse(pr["mergedAt"]) - isoparse(pr["createdAt"]) for pr in closed_prs],
# dtype="m8[m]").view("int64") / (60 * 24) # days
#lifetimes_closed.sort()
# Use the newest issue to guess a time when the data was generated.
# Can this logic be improved?
current_time = isoparse(max(iss["createdAt"] for iss in issues))
open_prs = [pr for pr in prs if pr['state'] == 'OPEN']
age_open = np.array(
[current_time - isoparse(pr["createdAt"]) for pr in open_prs],
dtype="m8[m]").view("int64") / (60 * 24) # days
age_open.sort()
fig, ax = plt.subplots(figsize=(6, 4))
number_merged = np.arange(1, len(lifetimes_merged)+1)[::-1]
ax.step(lifetimes_merged, number_merged, label="Merged")
#ax.step(lifetimes_closed, np.arange(1, len(lifetimes_closed)+1)[::-1])
number_open = np.arange(1, len(age_open)+1)[::-1]
ax.step(age_open, number_open, label="Open")
# Find the first point where closed have a bigger survival than open PRs:
all_lifetimes = np.concatenate([lifetimes_merged, age_open])
all_lifetimes.sort()
number_merged_all_t = np.interp(all_lifetimes, lifetimes_merged, number_merged)
number_open_all_t = np.interp(all_lifetimes, age_open, number_open)
first_idx = np.argmax(number_merged_all_t < number_open_all_t)
first_time = all_lifetimes[first_idx]
ax.vlines(
[first_time], 0, 1, transform=ax.get_xaxis_transform(), colors='k',
zorder=0, linestyle="--")
ax.annotate(
f"{round(first_time)} days",
xy=(first_time, number_open_all_t[first_idx]),
xytext=(5, 5), textcoords="offset points",
va="bottom", ha="left")
ax.legend()
ax.set_xlabel("Time until merged or time open [days]")
ax.set_ylabel(r"# of PRs open this long or longer")
ax.set_xscale("log")
fig.autofmt_xdate()
fig.tight_layout();
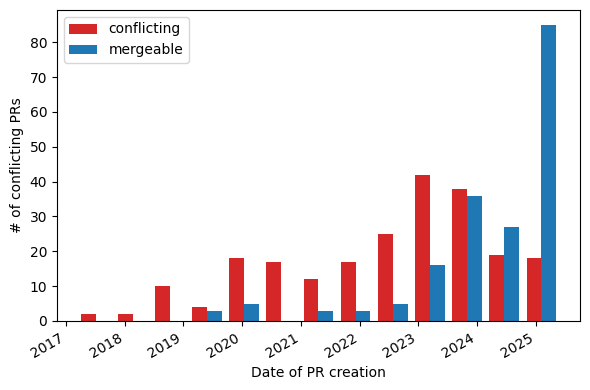
Mergeability of Open PRs#
Show code cell source
open_prs = [pr for pr in prs if pr["state"] == "OPEN"]
# The GraphQL query does not reliably return information on PR mergeability.
# Warn if there are problems
if any([pr["mergeable"] == "UNKNOWN" for pr in open_prs]):
warnings.warn(
(
"\n\nThe data contains PRs with unknown merge status.\n"
"Please re-download the data to get accurate info about PR mergeability."
),
UserWarning,
stacklevel=2,
)
conflicting_prs = [isoparse(pr["createdAt"]) for pr in open_prs if pr["mergeable"] == "CONFLICTING"]
mergeable_prs = [isoparse(pr["createdAt"]) for pr in open_prs if pr["mergeable"] == "MERGEABLE"]
fig, ax = plt.subplots(figsize=(6, 4))
ax.hist(
[conflicting_prs, mergeable_prs],
bins="auto",
histtype="bar",
label=("conflicting", "mergeable"),
color=("tab:red", "tab:blue"),
)
ax.legend()
ax.set_xlabel("Date of PR creation")
ax.set_ylabel(r"# of conflicting PRs")
fig.autofmt_xdate()
fig.tight_layout();
Number of PR participants#
Show code cell source
# Get the lifetimes and number of participants for merged PRs
lifetimes = np.array(
[isoparse(pr["mergedAt"]) - isoparse(pr["createdAt"]) for pr in merged_prs],
dtype="m8[h]",
)
num_participants = np.array([pr["participants"]["totalCount"] for pr in merged_prs])
title = "Distribution of lifetimes for merged PRs based on the number of participants"
p = figure(width=600, height=300, title=title)
p.xgrid.grid_line_color = None
p.xaxis.ticker = sorted(np.unique(num_participants))
p.yaxis.axis_label = "PR lifetime (hours)"
p.scatter(x=num_participants, y=lifetimes.astype(int), size=9, alpha=0.4)
show(p)
Where contributions come from#
There have been a total of 12187 merged PRs[1] submitted by 1484 unique authors. 1057 (71%) of these are “fly-by” PRs, i.e. PRs from users who have contributed to the project once (to-date).
Show code cell source
# Remap PRs by author
contributions_by_author = defaultdict(list)
for pr in merged_prs:
author = pr["author"]["login"]
contributions_by_author[author].append(pr)
num_merged_prs_per_author = np.array(
[len(prs) for prs in contributions_by_author.values()]
)
num_flybys = np.sum(num_merged_prs_per_author == 1)
glue("matplotlib_num_merged_prs_with_known_authors", len(merged_prs))
glue("matplotlib_num_unique_authors_of_merged_prs", len(contributions_by_author))
glue("matplotlib_num_flyby", percent_val(num_flybys, len(num_merged_prs_per_author)))
Show code cell source
title = "Distribution of number of merged PRs per contributor"
x = ["1", "2", "3", "4", "5", "6 - 10", "10 - 20", "20 - 50", "> 50"]
bedges = np.array([0, 1, 2, 3, 4, 5, 10, 20, 50, sum(num_merged_prs_per_author)]) + 0.5
y, _ = np.histogram(num_merged_prs_per_author, bins=bedges)
p = figure(
x_range=x,
y_range=(0, 1.05 * y.max()),
width=670,
height=400,
title=title,
tooltips=[(r"# PRs merged", "@x"), ("# contributors", f"@top")],
)
p.vbar(x=x, top=y, width=0.8)
p.xaxis.axis_label = "# Merged PRs per user"
p.yaxis.axis_label = "# of unique contributors with N PRs merged"
show(p)
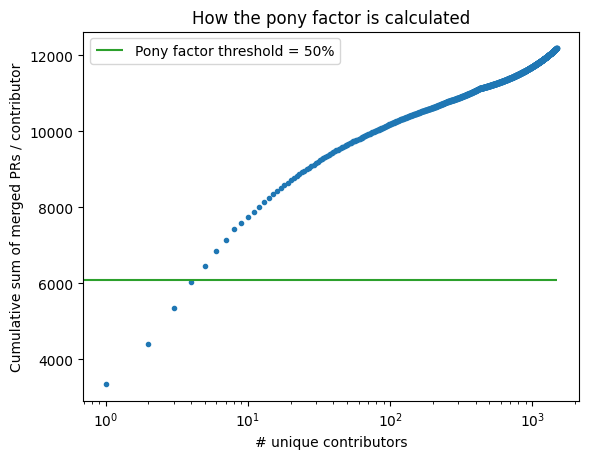
Pony factor#
Another way to look at these data is in terms of the pony factor, described as:
The minimum number of contributors whose total contribution constitutes a majority of the contributions.
For this analysis, we will consider merged PRs as the metric for contribution. Considering all merged PRs over the lifetime of the project, the pony factor is: 5.
Show code cell source
# Sort by number of merged PRs in descending order
num_merged_prs_per_author.sort()
num_merged_prs_per_author = num_merged_prs_per_author[::-1]
num_merged_prs = num_merged_prs_per_author.sum()
pf_thresh = 0.5
pony_factor = np.searchsorted(
np.cumsum(num_merged_prs_per_author), num_merged_prs * pf_thresh
) + 1
fig, ax = plt.subplots()
ax.plot(
np.arange(len(num_merged_prs_per_author)) + 1,
np.cumsum(num_merged_prs_per_author),
"."
)
ax.set_title(f"How the pony factor is calculated")
ax.set_xlabel("# unique contributors")
ax.set_xscale("log")
ax.set_ylabel("Cumulative sum of merged PRs / contributor")
ax.hlines(
xmin=0,
xmax=len(contributions_by_author),
y=num_merged_prs * pf_thresh,
color="tab:green",
label=f"Pony factor threshold = {100 * pf_thresh:1.0f}%",
)
ax.legend();
glue("matplotlib_pony_factor", str(pony_factor))