astropy#
# For interactive plots
from bokeh.plotting import figure, show, output_notebook
from bokeh.models import TeX
output_notebook()
A snapshot of the development on the astropy project.
Issues#
query_date = np.datetime64("2020-01-01 00:00:00")
# Load data
with open("devstats-data/astropy_issues.json", "r") as fh:
issues = [item["node"] for item in json.loads(fh.read())]
glue("devstats-data/astropy_query_date", str(query_date.astype("M8[D]")))
New issues#
2682 new issues have been opened since 2020-01-01, of which 1899 (71%) have been closed.
The median lifetime of new issues that were created and closed in this period is 185 hours.
query_date = np.datetime64("2020-01-01 00:00:00")
# Load data
with open("devstats-data/astropy_issues.json", "r") as fh:
issues = [item["node"] for item in json.loads(fh.read())]
glue("astropy_query_date", str(query_date.astype("M8[D]")))
Time to response#
Of the 2682 issues that are at least 24 hours old, 2309 (86%) of them have been commented on. The median time until an issue is first responded to is 1 hours.
First responders#
| Contributor | # of times commented first | |
|---|---|---|
| 174 | pllim | 767 |
| 101 | github-actions | 316 |
| 146 | mhvk | 209 |
| 160 | neutrinoceros | 123 |
| 185 | saimn | 88 |
| 164 | nstarman | 61 |
| 193 | taldcroft | 60 |
| 63 | astrofrog | 54 |
| 94 | eerovaher | 48 |
| 3 | Cadair | 45 |
Pull Requests#
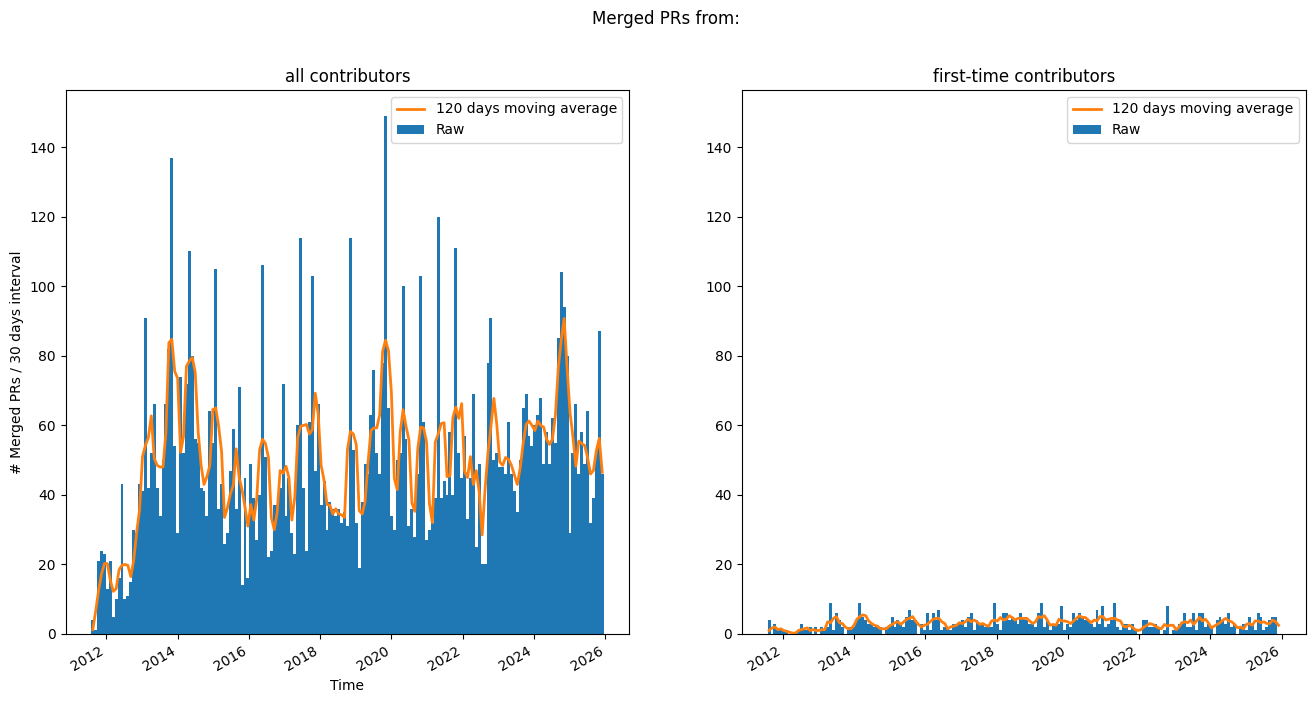
Merged PRs over time#
A look at merged PRs over time.
/tmp/ipykernel_4716/842352325.py:3: UserWarning: no explicit representation of timezones available for np.datetime64
merge_dates = np.array([pr['mergedAt'] for pr in merged_prs], dtype=np.datetime64)
PR lifetime#
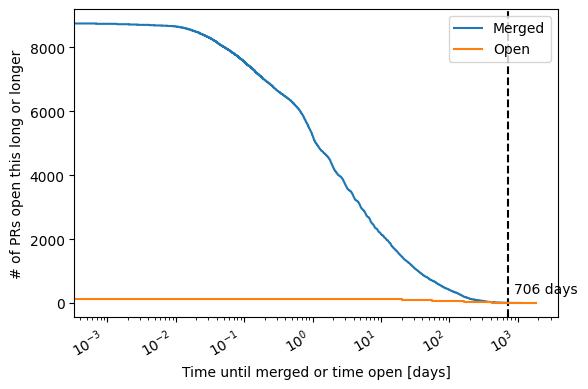
The following plot shows the “survival” of PRs over time. That means, the plot shows how many PRs are open for at least these many days. This is separated into PRs that are merged and those that are still open (closed but unmerged PRs are not included currently).
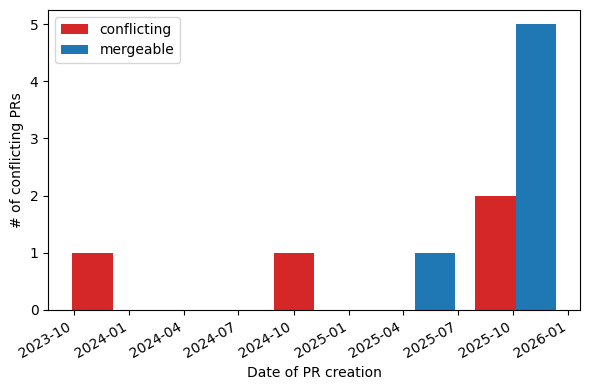
Mergeability of Open PRs#
/opt/buildhome/.local/share/mise/installs/python/3.13.11/lib/python3.13/site-packages/IPython/core/interactiveshell.py:3701: UserWarning:
The data contains PRs with unknown merge status.
Please re-download the data to get accurate info about PR mergeability.
exec(code_obj, self.user_global_ns, self.user_ns)
Number of PR participants#
Where contributions come from#
There have been a total of 8767 merged PRs[1] submitted by 540 unique authors. 301 (56%) of these are “fly-by” PRs, i.e. PRs from users who have contributed to the project once (to-date).
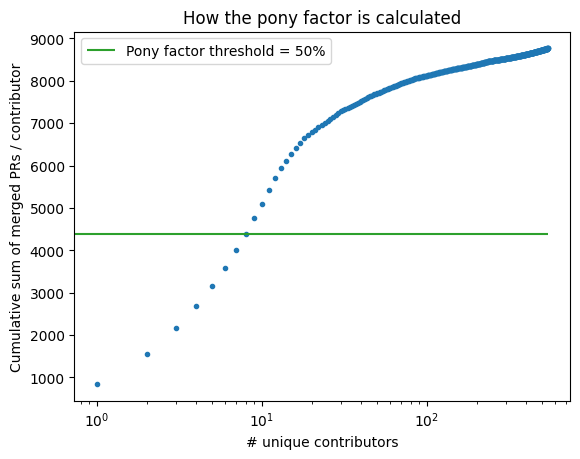
Pony factor#
Another way to look at these data is in terms of the pony factor, described as:
The minimum number of contributors whose total contribution constitutes a majority of the contributions.
For this analysis, we will consider merged PRs as the metric for contribution. Considering all merged PRs over the lifetime of the project, the pony factor is: 9.